It has come to my attention that there is still at least one group of people that doesn’t know how to responsibly deal with vulnerability reports. No, I’m not talking about the security researchers, the blackhats, or the script kiddies. It’s true that there is already alot of controversy surrounding proper (or responsible) disclosure etiquette, but that doesn’t concern the group I’m referring to right now. I’m talking about the maintainer of the resource that the vulnerability report is for. That means you, project maintainers!
Before Receiving a Report
One of the biggest difficulties I’ve been having lately is finding contact information for a project maintainer or their security contact. On multi-developer projects, there should be at least one person who is responsible for fielding security-related reports that come in. They should have the ability to put fixes for security vulnerabilities on high priority for the developers.
Your security person’s email should be easy to find or guess. For example, Google’s is security@google.com and this address is easy to find. You could also achieve this effect by using support/bug report forums, but be sure that any bug or report marked as security-related should be automatically hidden from public view. Regardless of if you decide to use a dedicated email box/alias or support forums for your security reports, it is most important to make someone responsible for making sure that security reports are reacted to quickly and professionally.
After Receiving a Report
As soon as the first human has eyes on the report, it should be assigned to an individual and a confirmation should be sent to the person who provided it. Here’s is one such confirmation:
Thank you for reporting this to us! We have opened a security investigation to track this issue. The case number for your tracking is MSRC [XXXX]. XXXX is the Security Program Manger assigned to the case and he will be working with you and the Microsoft.com team to investigate the issue. She will be following up with you shortly.
This step is super important because many of the people who take the time to report vulnerabilities to the vendor are only just waiting to release the report to the public. You don’t want to still be working on the fix when the news of your project’s security flaw is released.
Once you have a someone assigned to the bug, have them send a brief introduction. I never received my introduction from “XXXX” above, so I sent another email inquiring on the status of the bug. Here is the response:
Thank you very much for your message! My name is YYYY and I have taken over this case from XXXX. Earlier this week, the online services team has started testing a fix for the original issue you have reported, and we are currently verifying this, which includes variation testing and a review of the whole page. The added details you have provided to us in the below message will certainly help us in this process, so thanks a lot!
I will contact you as soon as the fix is deployed, and of course, if you have any further information or questions, please don’t hesitate to let us know.
This email is short, brief, yet contains all the information I would ever want to know. In particular it includes:
- An actual person I can continue to provide information to
- The status of the vulnerability/bug
- The next step(s) in their review process
- When I can expect to hear from them next
Just like the MSRC said I would, I heard from them when the fix made it to production. (In case you were wondering, it was 5 calendar days later.) At this point, they made arrangements to acknowledge me on the “Security Researchers Acknowledgment” page. While this is certainly a nice perk, you don’t have to do this.
A valid question at this point is “How long do I have to fix this vulnerability?”
It depends, but as the vendor that’s up for you to figure out. If you’re receiving a vulnerability report from a non-public source, then consider yourself lucky. The person reporting the vulnerability likely believes in responsible disclosure (inherent of the fact that you got the report first) and will be willing to negotiate on the timeline. Be honest with this person. I once waited two months to report a minor SQL injection vulnerability in a trivial web application because the (sole) project maintainer was on vacation when I emailed him initially.
Summary (tl;dr)
Many of the security researchers who will reach out to you believe in responsible (but full) disclosure. That means that your project’s security flaws will make it to the public sooner or later. To ensure the best experience for your users and the preservation of your project’s reputation, you need to handle your vulnerability reports quickly and properly. That means:
- Making it easy to find out where to send vulnerability reports to
- Communicating with the source of the report to confirm receipt of their report
- Communicating with the source of the report your intentions for their report
- Who did the vulnerability get assigned to?
- What is the status of this vulnerability?
- What are the next steps in the review process for this vulnerability?
- When they can expect to hear from you next
- Communicating with the source when you believe the vulnerability is fixed
What is all boils down to is this: React quickly and keep open lines of communication between your project and the security researcher who took the time to report a vulnerability to you. If you do this, you’ll minimize the damage to your user base and your reputation.
 © uair01; some rights reserved.
© uair01; some rights reserved.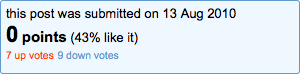
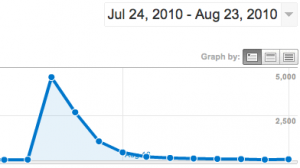
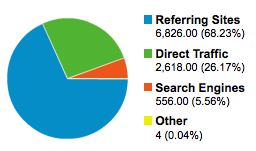
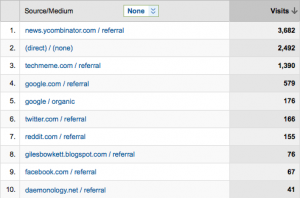
 And Hacker News loved it!
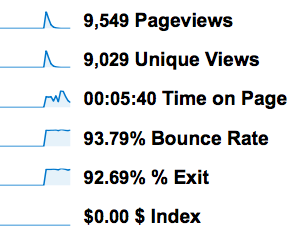
And Hacker News loved it! I also make use of Posterous’ “autopost” features and have all my new submissions get posted to Twitter and Facebook. According to Posterous, there were over 77 retweets of my article (most likely from the tweet storm that the Silicon Alley Insider bot and HN bots started) and 7 “likes” on Facebook.
Traffic
I also make use of Posterous’ “autopost” features and have all my new submissions get posted to Twitter and Facebook. According to Posterous, there were over 77 retweets of my article (most likely from the tweet storm that the Silicon Alley Insider bot and HN bots started) and 7 “likes” on Facebook.
Traffic