A term I hear often in the context of engineering and project management is “slack.” It’s often used to refer to a magical pool of time that all of a service’s upkeep, including maintenance and operations, is going to come out of. This is wrong though. Here’s why:
-
That’s not what slack is for
-
Mismanaged slack is equivalent to non-existent slack
What is it then?
I subscribe to the definition in Tom DeMarco’s Slack, which is “the degree of freedom required to effect change.”
Slack is something you maintain so that your team is responsive and adaptable, it is not “extra time” or “maintenance time.” If you are doing this, you are effectively allocating that time and thus eliminating your slack pool. Signs you or your team may be guilty of this:
-
You don’t make explicit allocations of time to operations or maintenance upkeep
-
You don’t “have enough time” to properly operate or maintain your services
-
You can’t solve problems or complete remediation items identified by your organization’s problem management program
So I should do nothing then?
Well, no. At least some of your slack needs to be spent idle though. Remember that the concept of slack is rooted in queueing theory. There’s a well-known relationship between utilization and response time. This relationship is exponential: The higher utilized your team is, the much higher your response time is! You can see it for yourself below:
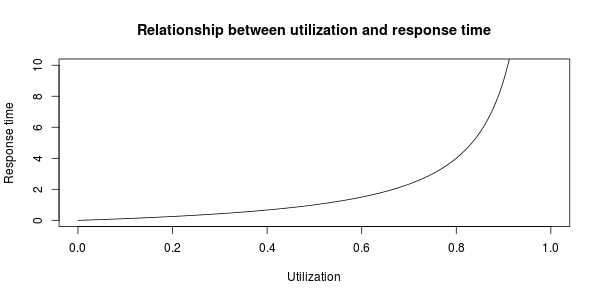
We can tell by looking at this graph that our responsiveness falls apart at about 70% utilization which means you should keep at least 30% of your time unallocated.
Unallocated? Why can’t I just devote 30% of my time to upkeep?
Because upkeep, the maintenance and operations of your service, are required activities. Entropy means that, unkept, your service will degrade over time. This entropy is accelerated if your service is experiencing growth. Your databases will bloat, your latency will increase, your 99.99% success rate will fall to 99.9% (or worse), your service will be difficult to add features to, and eventually your users will go somewhere else.
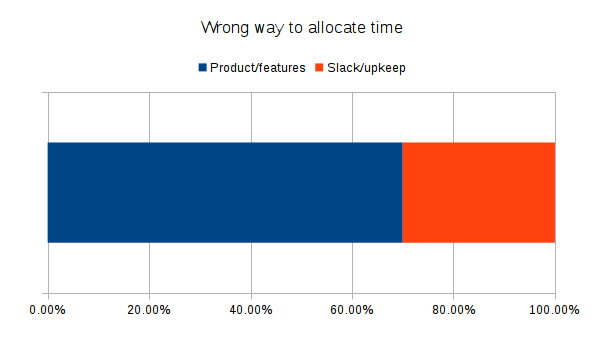
Instead of thinking about it like this:
Think about it like this:
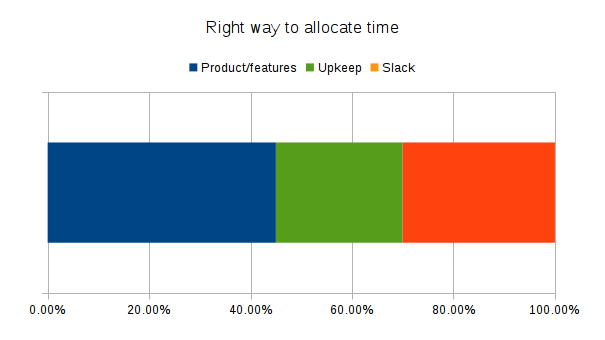
In this model, you explicitly allocate time to upkeep and maintain a slack pool.
How much time should I spend on upkeep versus product and feature work?
I don’t have a good guideline for you, sorry. You’ll need to determine this based on your organization’s or team’s goals and any SLAs you may have.
For example, if you’re operating a service with a service-level objective of meeting a 99.99% success rate (0.01% error rate) then you need to allocate more time to upkeep than a service targetting a 99.9% success rate, generally speaking.
Note that this will change and vary over time. If you’re already deep in technical debt, your upkeep allocation will need to be much higher to pay off some of your principal. Once you’ve done that, you’ll probably be able to meet your goals with a much lower allocation later on.
Call to action
I urge everyone to start thinking about slack and upkeep this way. Take a close look at your team’s goals and commitments and explicitly allocate time for reaching those goals. Doing so will allow your team to properly maintain the services which it operates while also being very responsive.